
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
Tags
- shell
- Bandit
- 보안
- 칼리 리눅스
- kali linux
- nomaltic place
- 리눅스 기초
- virtualbox
- VDI
- nomaltic
- Normaltic
- 노말틱
- kali
- Vitual Disk Image
- Error
- Bitnami
- Linux
- MariaDB
- 리눅스
- Virtual Box
- 칼리
- 네트워크
- mysql
- Web shell
- 기초
Archives
- Today
- Total
게으른 개발자
8강-2. Memory Management 2 본문
Noncontiguous allocation

- page
- 프로그램을 구성하는 메모리를 동일한 크기의 page로 잘라서 각각의 page 별로 물리적 메모리의 적당한 위치에 올라갈 수 있게 해 준다.
- page table
- page 기법에서 주소 변환을 위해서 사용된다.
- 논리적인 page 개수만큼 entry(명부, 명단?) 이 존재한다.
- entry는 테이블(배열)에서 사용하는 용어이다.
- 테이블(배열)은 인덱스를 이용해서 곧바로 접근할 수 있는 자료구조이다.
- entry는 테이블(배열)에서 사용하는 용어이다.
- 각각의 논리적인 페이지들이 물리적인 메모리에서 어디에 올라가 있는지 위치를 저장함.
- 논리적 page 번호
- 물리적 page frame 번호
- logical memory
- code , data , stack으로 구성됨.
- 중간에 메모리가 사용이 안되는 공간이 많이 존재한다.
- 이로 인해서 주소변환을 위한 page table이 낭비가 된다.

- cpu가 논리적인 주소를 주면 물리적인 주소로 바꿔야 한다.
- page 기법에서는 주소변환 할 때, page table를 사용한다.
- p: 논리적인 페이지 번호
- d : 페이지 내에서 얼마큼 떨어져 있는지 나타내는 offset
- 페이지 내에서 offset 부분은 주소 변환에서 영향이 없다.
- f : 페이지 프레임 번호
- 논리적인 페이지 번호에 해당하는 entry(위에서 p번째 entry)를 page table에서 찾아가면 f 가 나온다.
- 그러면 논리적인 주소를 물리적인 주소로 바꾸게 된다.




그러면 page table은 어디에 들어가야 할까?
- 프로그램을 구성하는 주소 공간을 페이지 단위로 자를 때, page 크기는 4KB
- 실제로는 프로그램이 100만 개의 페이지로 잘린다.
- page table의 entry가 100만 개 필요하다.
- 100만 개의 페이지 테이블은 너무 크기 때문에 레지스터에 못 들어간다.
- 캐시 메모리에도 못 들어간다.
- 따라서 페이지 테이블을 메모리에 집어넣는다.
- 프로그램마다 별도의 페이지 테이블이 존재해야 한다.
- 실제로는 프로그램이 100만 개의 페이지로 잘린다.

- MMU에 있는 레지스터가 page 기법에서는 어떻게 사용될까?
- relocation register, limit register
- Page table base register = PTBR
- Page table length register = PTLR
- ===> PTBR(메모리 상에서 페이지 테이블이 어디에 있는지 시작 주소를 저장 = 페이지 테이블의 시작위치), PTLR(페이지 테이블의 길이를 저장)
- 매번 메모리 접근을 하려면, 2번에 memory access가 필요하다.(비용이 크다)
- 1번째 : page table을 위한 주소변환을 위해서 메모리 접근
- 2번째 : 주소 변환이 됐으면 실제로 data/instruction 접근.
- 2번씩 메모리에 접근하면서 연산을 하기에는 속도가 느리므로, 속도 향상을 위해 별도의 하드웨어를 사용
- TLB : 메인 메모리와 cpu 사이에 있는 주소 변환을 하는 계층, 일종의 캐시이다.

- TLB
- 컴퓨터 구조에서 메인 메모리 위에 캐시 메모리가 있다.
- 캐시 메모리는 운영체제에게는 감추어진 계층이다.
- 메인 메모리에서 빈번히 사용되는 데이터를 캐시 메모리에 저장해서 cpu가 더 빨리 접근할 수 있게 함.
- 이런 캐시 메모리처럼 주소 변환을 위한 별도의 캐시를 두고 있는데, 그게 바로 TLB이다.
- TLB는 페이지 테이블에서 빈번히 참조되는 일부 entry를 캐싱을 하고 있다.
- 즉, 주소 변환을 위한 캐시 메모리이다. 메인 메모리보다 접근속도가 빠른 하드웨어로 되어있다.
- cpu가 논리적인 주소를 주게 되면
- 물리적 메모리상에 있는 페이지 테이블에 접근하기 전에 TLB를 먼저 검색해 본다.
- 만약 TLB에 저장이 되어있으면, TLB를 통해서 주소 변환이 이루어진다. [TLB hit]
- 이 경우에는 메모리를 한 번만 접근하면 된다.
- TLB에 없다면 페이지 테이블을 통해서 일반적인 주소 변환을 한다. [TLB miss]
- 2번의 메모리 접근 필요
- 논리적인 페이지 번호 P, P에 의해서 주소 변환된 Frame 번호 F ==> [ P, F ] : 이렇게 쌍으로 가지고 있어야 한다.
- 이 부분이 일반적인 페이지 테이블과 차이점이다.
- P, F를 쌍으로 가지고 있는 이유는 전체적인 데이터를 TLB에 저장하고 있지 않기 때문이다.
- 페이지 테이블에서는 p만 있다면 f를 찾을 수 있는데, TLB에서는 전체 데이터가 없어서 불가능하다. 그래서 [ P, F ] 이렇게 쌍으로 가지고 있어야 한다.
- 주소 변환을 위해서 TLB에서는 특정 항목을 검색하는 게 아니라 전체 항목을 검색해야 한다.
- p가 있는지 확인해야 하기 때문이다.
- 전체 search 필요
- 전체를 search 하는데 시간이 오래 걸린다.
- 시간이 오래 걸리는 걸 막기 위해서 병렬 탐색( parallel search)을 할 수 있는 Associative register를 이용해서 구현을 한다.
- 페이지 테이블을 이용한 주소 변환은 전체 search 할 필요가 없다.
- P : 배열의 인텍스 => P를 가지고 임의접근(random access)이 가능해집니다.
- 주소 변환이 바로 이루어진다.

- 프로세스마다 주소 변환 정보가 다르기 때문에 문맥 교환(context switch)이 일어날 때 TLB를 flush 해줘야 한다.
- 페이지 테이블은 각 프로세스마다 존재한다.
- 프로세스 별로 논리적인 주소체계가 다르기 때문이다.
- 페이지 테이블은 각 프로세스마다 존재한다.

- TLB에 접근하는 시간은 메인 메모리에 접근하는 시간보다 작다.
- α : 1에 가까운 값 => 높은 비율 | ε : 굉장히 작은 값

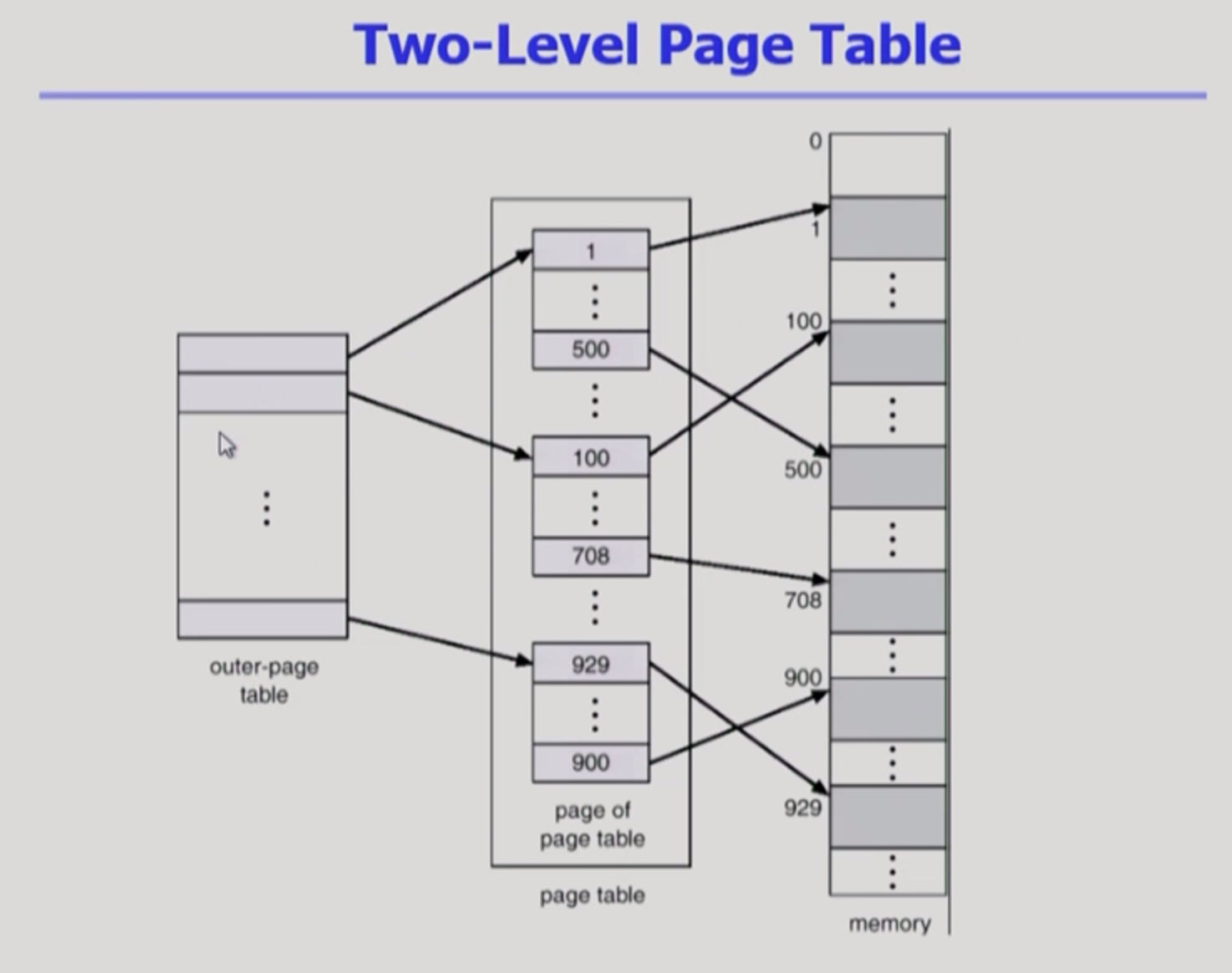
- 페이지 테이블이 2단계로 이루어져 있다.
- 왜 이런 2단계 페이지 테이블을 사용하는가?
- 컴퓨터에서는 보통 목적이 2가지
- 속도 증가
- 공간을 줄이기
- 2단계 페이지 테이블에서는 속도는 더 걸림.
- 속도는 증가되지 않음
- 페이지 테이블을 위한 공간이 줄어든다.
- 이것이 2단계 페이지 테이블을 사용하는 이유이다.
- 컴퓨터에서는 보통 목적이 2가지
- 왜 이런 2단계 페이지 테이블을 사용하는가?

- 현대 컴퓨터에서는 메모리 주소체계가 굉장히 크다.
- 메모리는 주소단위가 바이트이다.

프로그램마다 가지고 있는 virtual memory의 최대 크기는 얼마까지 가능할까?
메모리를 표시하는 몇 비트 주소체계를 쓰냐에 따라서 달라진다.
- 주소를 32비트를 쓰면?
- 32비트로 표현 가능한 서로 다른 표현 방법은 몇 가지 일까?=> 2^32
- 메모리 주소가 0번지~2^32-1까지 메모리 주소를 매길 수 있다.
- 2^10 = K
- 2^20 = M
- 2^30 = G , [ (2^2)*(2^30) B(바이트) = 4GB ]를 표시할 수 있다
- 각 프로그램마다 가질 수 있는 최대 메모리 크기는 4GB
- 4GB로 표시할 수 있는 총공간을 page 단위로 쪼갬
- 각각의 페이지 단위가 4KB
- 전체 페이지 개수는 1M 개의 페이지이다.
- 백만 개의 page entry를 물리적 메모리에 넣으면 공간 낭비가 심하다.
- 각 page entry는 4B, page entry는 백만 개 있으므로 4B * 1M = 4MB(page table의 크기)
- 각 프로그램마다 페이지 테이블을 위해서 4MB의 공간이 필요하다.
- 그러나 대부분 프로그램은 4G의 주소 공간 중 일부분만 사용하기 때문에 page table의 공간이 낭비가 된다.
- 따라서 이런 이유로 Two Level Page Table를 사용한다.
- 아래 이미지에서 사각형 하나를 page entry라고 함. 여기서는 4개의 page entry가 있다.
- 백만 개의 page entry를 물리적 메모리에 넣으면 공간 낭비가 심하다.


- p1 : 서울, p2 : 서대문구, 강남구, 동작구. ...
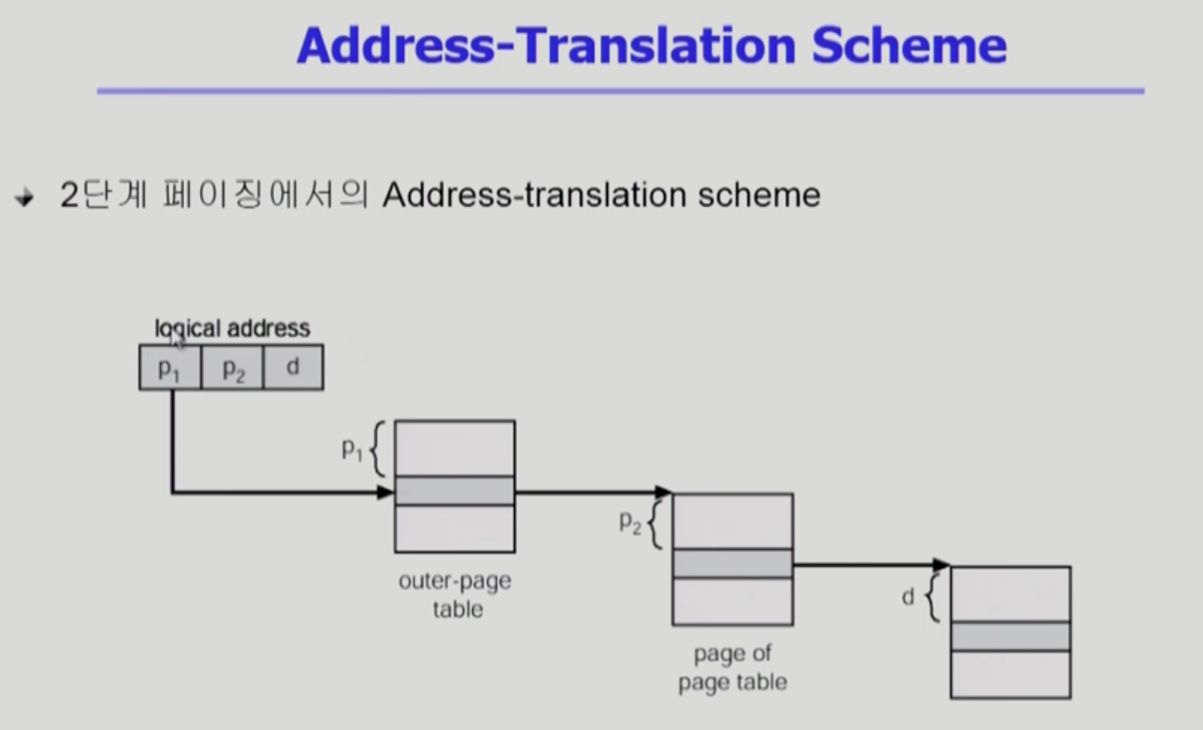
- p1 : 논리적인 주소에서 바깥쪽 테이블의 인덱스 번호
- p1번째 entry를 가서 주소변환정보를 얻는다.
- 안쪽 페이지 테이블 중에서 어떤 페이지 테이블인지 지정을 해줌.
- p2 : 안쪽 페이지 테이블의 페이지 번호
- 위에서부터 몇 번째 entry 인지 구분하는 숫자이다.


- 안쪽 테이블의 크기가 페이지 크기랑 똑같다.
- 안쪽 페이지 테이블은 테이블 자체가 페이지화 돼서, 페이지 어딘가에 들어가 있게 된다.
- 페이지 크기가 4KB 이기 때문에 안쪽 페이지 테이블의 크기도 4KB이다.
- 보통 페이지 테이블의 entry 하나 크기가 4B, entry의 개수는 1K 개를 집어넣을 수 있다.

- 페이지 크기는 4KB
- 4KB 안에서 Byte 단위로 주소 구분을 하려면 몇 비트가 필요한가?
- 4K = 2^12 개의 바이트를 구분해야 한다. 따라서 12bit가 필요하다.
- 4KB 안에서 Byte 단위로 주소 구분을 하려면 몇 비트가 필요한가?

- 안쪽 페이지 테이블이 페이지화 돼서 메모리에 들어간다.

- 1K 개를 구분하기 위해서는 10bit가 필요하다.
- 만약 64bit 주소체계를 쓰면?
- 나머지 조건은 32bit 주소 체계와 동일하다고 하자
- d = 12, p2 = 10, p1 = 64 - 12 - 10 = 42
- Two Level Page Table
- 시간은 더 걸리지만 페이지 테이블을 위한 공간은 줄인다.

- 프로그램을 구성하는 공간 중에서 상당 부분은 사용을 안 함.


- 배열의 칸을 중간에 삭제시키면 인덱스가 제대로 작동을 안 하는 원리와 같다.
- 따라서 Maximum 로지컬 메모리의 크기만큼 page entry가 만들어져야 한다.
- 그러나 2단계 페이징 기법에서는 위에 문제를 해결할 수 있다.
- 바깥쪽 페이지 테이블은 전체 논리적 메모리 크기만큼 만들어진다.
- 실제로 사용되지 않는 주소에 대해서는 안쪽 페이지 테이블은 안 만들어지고, outter 테이블의 포인터는 NULL 이 된다.
- 바깥쪽 테이블 : K개의

'cs > 운영체제' 카테고리의 다른 글
| 8강-4. Memory Management 4 (0) | 2023.11.11 |
|---|---|
| 8강-3. Memory Management 3 (0) | 2023.11.10 |
| 8강-1. Memory Management 1 (0) | 2023.11.07 |
| 7강-2. Deadlock 2 (1) | 2023.11.07 |
| 7강-1. Deadlock 1 (1) | 2023.11.06 |
'cs/운영체제' Related Articles
more



