
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
Tags
- kali
- 리눅스 기초
- Normaltic
- 네트워크
- Error
- 칼리 리눅스
- 칼리
- 노말틱
- shell
- Web shell
- nomaltic place
- MariaDB
- Virtual Box
- nomaltic
- 리눅스
- mysql
- Bitnami
- Linux
- Bandit
- virtualbox
- Vitual Disk Image
- VDI
- kali linux
- 보안
- 기초
Archives
- Today
- Total
게으른 개발자
11강 - 1. File System 1 본문

- File
- 정의 : 관련정보를 이름을 가지고 저장한다.
- 비휘발성 보조기억장치에 저장.
- 생성, 읽기, 쓰기, 삭제
- 파일은 여러 개의 바이트로 구성이 된다.
- 어느 위치를 읽는지, 쓰는지를 가리키는 포인터가 있다.
- 대개는 파일 읽으면 시작 부분을 읽게 되는데, 한번 읽고 나면 그 파일을 가리키는 포인터가 그다음 부분을 가리키게 된다. 쭉 읽게 되면 위치 포인터는 그다음 위치로 자동 이동을 한다.
- reposition(lseek) : 필요에 따라서 파일의 시작 부분 또는 현재의 위치 포인터 부분이 아니라 다른 부분부터 읽거나 쓰고 싶을 때. 그런 파일의 접근하고 있는 위치를 수정해 주는 연산.
- open : open을 하고 read, write을 해야 한다. (인터페이스가 이렇게 하도록 되어있다.)
- open은 disk에서 내용을 올려놓는 게 아니다.
- 파일의 메타데이터(metadata or file attribute)를 메모리로 올려놓는 작업이다.
- 파일을 관리하기 위한 각종 정보들
- close : 읽고, 쓰고 다했으면 파일을 close 해라
- File system
- 파일을 관리하는 소프트웨어 부분
- 파일 자체의 내용 관리.
- 파일의 메타데이터도 저장.
- Directory
- 디렉터리도 하나의 파일이다.
- 파일의 내용이 디렉터리 밑에 있는 파일들이 어떤 건지에 해당하는 정보를 내용으로 하는 파일
- 일반 파일
- 예시 ) 음악 파일
- 내용 : 음악 | 메타데이터 : 그 파일의 이름, 접근 권한 등등
- 예시 ) 음악 파일
- 디렉터리 파일
- 내용 : 그 디렉터리 밑에 존재하는 파일들의 정보(메타데이터) | 메타데이터 : 그 파일(디렉터리)의 이름, 접근 권한, 저장위치(파일의 내용을 가리키는 포인터) 등등
- Partition = 논리적인 디스크
- 디스크의 용도는 크게 2가지이다
- 1. file system
- 2. swapping
- 디스크의 용도는 크게 2가지이다
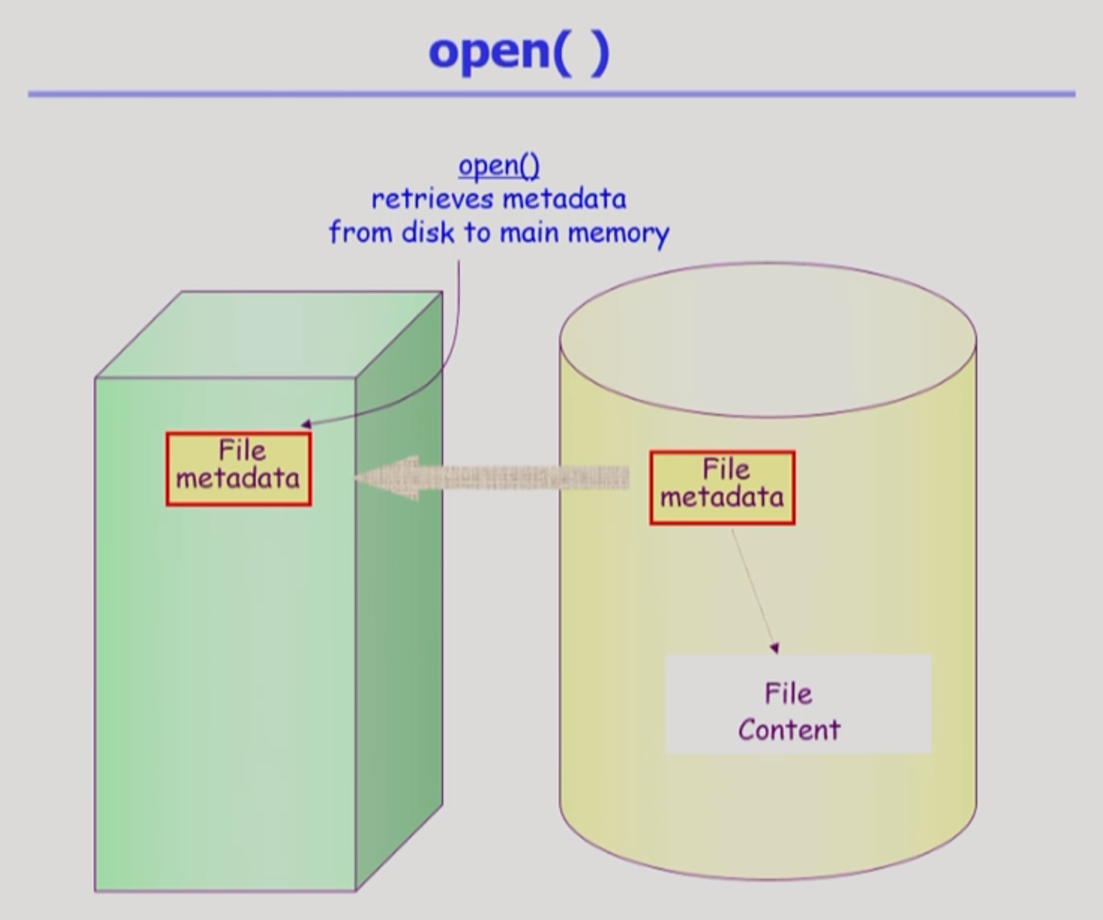
- open()
- 파일의 메타데이터를 메모리로 올려놓는 것
- 논리적인 디스크 안에 파일 시스템이 있으면, 그 파일 시스템의 특정파일의 메타데이터와 내용이 저장되어 있다.


- open 도 system call이다. read, write도 i/o를 하는 system call
- open file table : open 한 파일이 어떤 건지를 관리하는 global 한 테이블
- root 디렉터리의 메타데이터는 미리 알려져 있다.
- 운영체제가 root 디렉터리의 메타데이터가 어디에 있는지 알고 있다.
- 따라서 root 디렉터리의 메타데이터를 메모리에 올린다. ( root를 먼저 open)
- root의 메타데이터를 열어보면 root 디렉터리의 실제 내용이 어디에 있는지 위치를 찾을 수 있다.
- 그러면 root의 content가 무엇인가?
- 디렉토리 밑에 있는 파일들의 메타데이터를 가지고 있다.
- 그러면 root의 content가 무엇인가?
- 이런 식으로 원하는 파일의 메타데이터를 찾아서 메모리에 올린다. - open 끝
- 그러면 open()은 어떤 결괏값을 return 해줄까?
- 각 프로세스마다 그 프로세스가 open 한 file들에 대한 메타데이터를 가리키는 포인터를 가지고 있는 일종의 배열이 정의되어 있다.
- 해당 파일의 메타데이터를 가리키는 포인터가 배열 어딘가에 만들어진다.
- 그 배열에서 몇 번째 인덱스에 포인터가 들어가게 되는데, 인덱스가 바로 fd(file descriptor)이다.
- 그 fd를 사용자 프로세스에게 리턴을 해준다.
- 사용자 프로세스는 fd를 가지고 read/write 요청을 할 수 있다.
- 예를 들어 b라는 파일을 읽어오고 싶을 때, argument로 파일 이름을 적는 게 아니라 fd를 넣어준다.
- read(fd...)는 시스템 콜이므로 cpu가 운영체제에게 넘어감.
- A의 PCB에 가서 해당 fd에 대응하는 file metadata를 open file table에서 찾는다.
- b의 메타데이터를 통해서 해당 파일의 위치정보(디스크에서 어디에 있는지 알려주는 정보)를 통해서 내용을 읽어온다.
- 만약 그냥 읽어오라고 했으면, 시작 위치부터 읽어온다. (read(fd..)에서 요청한 용량만큼 읽어온다)
- 그 내용을 읽어서 사용자 프로그램에게 직접 주는 게 아니다! 운영체제가 자신의 메모리 공간 일부에다가 먼저 읽어놓는다. [버퍼 캐싱]
- 그런 다음에 사용자 프로그램에게 그 내용을 copy 해서 전달해 준다. - read 작업 끝
- 만약에 다른 프로그램이 동일한 파일의 동일한 위치를 요청하면?
- 기존에 있던 놈을 copy 해서 전달해 준다.
- 이러면 disk에 접근할 필요가 없어진다.
- 이걸 [버퍼 캐싱]이라고 한다.
- 파일 시스템의 버퍼 캐시는 요청한 내용이 [버퍼 캐시] 안에 있든 없든 간에 운영체제에게 cpu 제어권이 넘어간다.
- 이런 버퍼캐싱 환경에서는 LRU, LFU 알고리즘을 자연스럽게 사용할 수 있다.
- 왜냐하면 모든 정보를 운영체제가 알고 있기 때문이다.(페이징 시스템에서 LRU, LFU 알고리즘을 못 쓰고, clock 알고리즘을 사용한 것과 대조적이다.)
- 이런 버퍼캐싱 환경에서는 LRU, LFU 알고리즘을 자연스럽게 사용할 수 있다.
- 각 프로세스마다 그 프로세스가 open 한 file들에 대한 메타데이터를 가리키는 포인터를 가지고 있는 일종의 배열이 정의되어 있다.
- per - process file descriptor table : 프로세스마다 하나씩 존재
- system - wide open file table : 시스템 전체에 하나 존재
- 운영체제 구현에 따라서 테이블이 3개 있을 수도 있다.
- 왜 그런가?
- 메타데이터가 디스크에 있을 때는 파일 이름, 유형, 저장된 위치, 파일 사이즈, 접근 권한(읽기/쓰기/실행), 시간(생성/변경/사용), 소유자 등 이런 자료만 필요하다.
- 그러나 메모리에 올려놓게 되면 여기에 추가적으로 메타데이터가 필요하다.
- 현재 이 프로세스가 이 파일의 어느 위치를 접근하고 있는지 알려주는 offset을 운영체제가 가지고 있어야 한다.
- 각 프로그램마다 같은 파일을 읽고 있더라도, 읽고 있는 부분이 다를 수 있기 때문이다
- 그래서 offset은 프로세스마다 별도로 가지고 있어야 한다.
- 프로세스가 어디를 접근하고 있는지 별도로 가지고 있는 offset을 관리하는 테이블이 추가로 필요하다.
- 왜 그런가?

- 파일의 접근 권한(3가지)
- 파일에 대한 접근 권한은 권한이 누구한테 있냐, 접근 연산이 어떤 것이 가능한지 2가지를 같이 가지고 있어야 한다.
- Access control Matrix
- 행렬(여기서 이 행렬은 희소행렬이 될 것이다. 희소 행렬(Sparse Matrix)은 행렬의 원소 중에 많은 항들이 '0'으로 구성되어 있는 행렬이다.)
- 파일들은 엄청 많을 텐데, 특정 사용자가 본인만 사용하려고 만들어 놓은 파일은 다른 사람이 접근권한을 가질 수 없다.
- 그래서 행렬의 칸을 만들면 낭비가 된다. - 공간 낭비
- 앞에서 행렬은 낭비가 되어서 비효율적이기 때문에 linked list로 구현한다.
- [Access control list]
- 파일을 주체로 해당 파일에 접근권한이 있는 사용자들을 linked list로 묶어둔다.
- 사용 권한이 없는 많은 사용자들은 연결할 필요가 없다.
- [Capability list]
- 사용자를 주체로 linked list를 만들 수 있다.
- [Access control list]
- 그러나 앞에 있는 방법을 쓰더라도 부가적인 오버헤드가 크다.
- 행렬(여기서 이 행렬은 희소행렬이 될 것이다. 희소 행렬(Sparse Matrix)은 행렬의 원소 중에 많은 항들이 '0'으로 구성되어 있는 행렬이다.)
- Grouping
- 일반적인 운영체제에서 파일 접근권한에 사용하는 방식
- 그룹핑에서는 모든 사용자에 대해서 접근권한을 다루는 게 아니다.
- 각각의 파일에 대해서 3가지로 나눈다.
- owner : 소유주에 대해서 read/write/execution(실행) 권한이 있는지 표시
- group : 사용자와 동일 그룹에 속한 사용자에 대해서 read/write/execution 권한이 있는지 표시
- public : 나머지 외부 사용자에 대해서 read/write/execution 권한이 있는지 표시
- 9개의 비트로 표시할 수 있다.
- Password
- 모든 파일에 대해서 password를 통해서 관리한다.
- 암호가 굉장히 여러 개 생길 수 있다.

- 하나의 물리적인 디스크를 여러 개의 논리적인 디스크로 나눌 수 있다.
- 각각의 논리적인 디스크에는 파일 시스템을 설치해서 사용할 수가 있다.
- 만약 다른 파티션에 설치되어 있는 파일 시스템을 접근하려면?
- Mounting 연산 사용
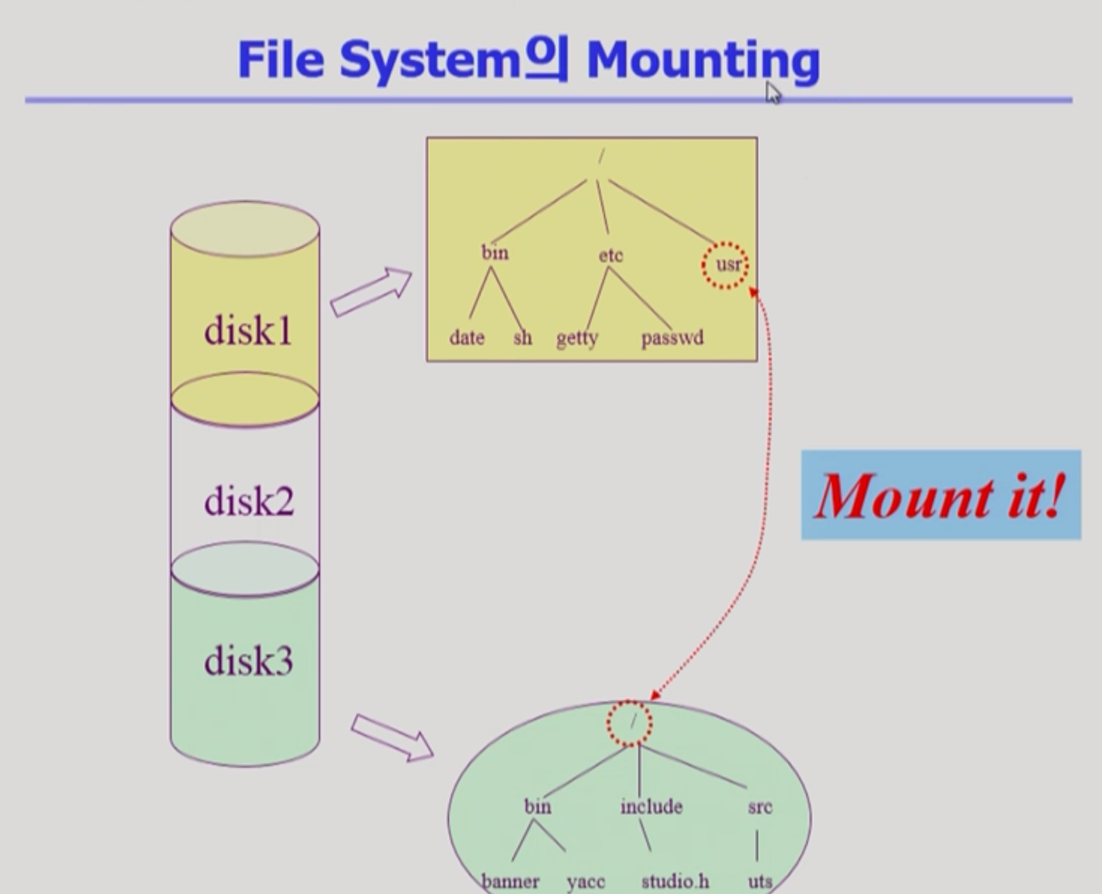
- root file system에서 특정 디렉터리 이름에다가 또 다른 파티션에 있는 file system을 Mount를 해주면
- Mount 된 디렉터리를 접근하게 되면, 또 다른 파일 시스템의 루트 디렉터리를 접근할 수 있다.

- 아무리 직접접근이 되는 매체라도 관리를 어떻게 하냐에 따라 순차접근만 가능한 경우도 있다.
'cs > 운영체제' 카테고리의 다른 글
| 11강 - 3. File System Implementations 2 (0) | 2023.11.15 |
|---|---|
| 11강 - 2. File System Implementations 1 (0) | 2023.11.15 |
| 10강 - 2. Virtual Memory (1) | 2023.11.13 |
| 10강 - 1. Virtual Memory (0) | 2023.11.12 |
| 8강-4. Memory Management 4 (0) | 2023.11.11 |
'cs/운영체제' Related Articles
more



